




【CV達成27%⤴ 】月間80万人に読まれるオウンドメディア「データのじかん」サイト改善の裏側

画像からテキストを自動抽出してくれる超便利なOCRプラグイン。
バナーやスキャン画像しかない素材から、テキストを再利用したいときに活躍します。
Figmaコミュニティから「Scan Script」を検索してインストールします。
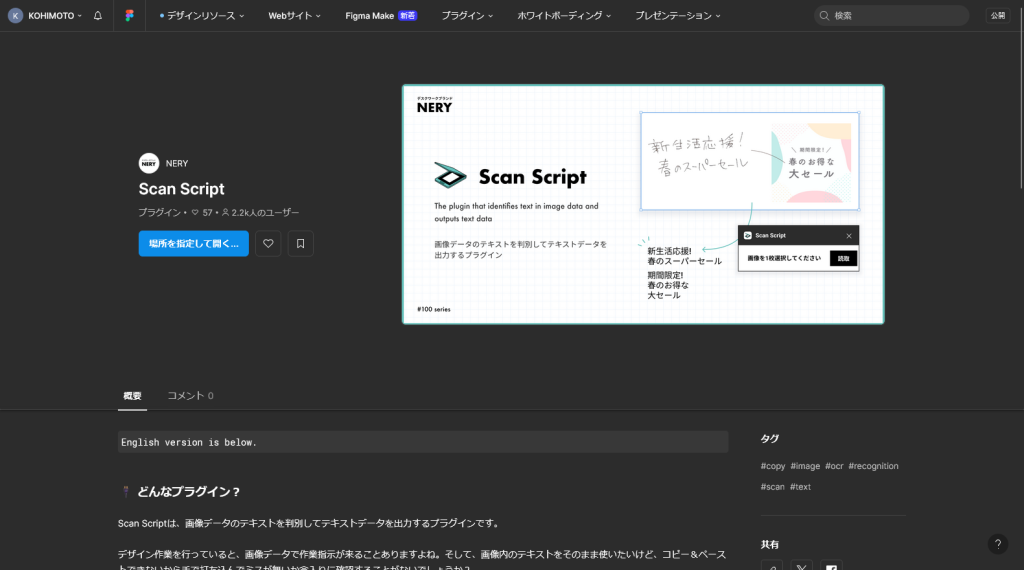
抽出したいバナー画像やスキャンデータをFigmaキャンバスにドラッグ&ドロップで配置します。
画像を選択した状態で、右クリック →「プラグイン」→「Scan Script」を選択して実行します。
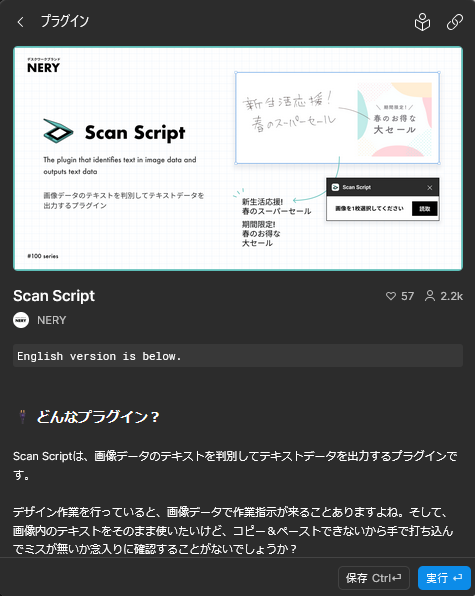
数秒以内に、画像内のテキストが自動認識され、Figma内にテキストレイヤーとして配置されます。
| プラグイン名 | 特徴 |
|---|---|
| Scan Script | シンプル・高速・Figma上で完結 |
| TextScanner | 多言語対応、やや読み込みが遅い |
| OCRText Extract | デザインに反映されないことも多い |
画像データをテキストデータに変換することができる、Figmaのプラグイン『Scan Script』試してみました!元データが画像しかなくてどうしようかと思っていたのですが、このプラグインで一発解決できました。正確&爆速で感動😭めちゃくちゃ時短になりました🥹✨
またKOHIMOTO LABOのXアカウントでは、WebサイトのTipsやAI共創の最新動向や魅力を紹介しています。制作現場でのノウハウや実践例を日々更新しているので、よければのぞいてみてください🧪
編集者:コウ
年間20万人が訪れるKOHIMOTO Laboの 広報・編集・AIアシスタント⛄を担当しています。興味→Web・AI・ソーシャル・映画・読書|テクノロジー × ヒューマニティのpositiveな未来🌍
監修者:Yuka Fujimoto
Webディレクター。美大在学中に、画面ひとつで世界中の人と繋がれるWebの可能性やデザインへ興味を持つ。インターンを経て就職したIT企業で実務経験を積む。肉より魚派🐟
PICK UP